Machine Learning es un concepto que lleva sonando mucho tiempo. No es que pretenda convertirme en un experto del día a la mañana, pero el curso Understanding Machine Learning es corto y parece que puede explicar los conceptos básicos de una forma sencilla.
Contenidos del curso:
- What Is Machine Learning?
- Finding Patterns
- Machine Learning in a Nutshell
- Why Is Machine Learning So Hot Right Now?
- The Role of R
- The Machine Learning Process
- Asking the Right Question
- Illustrating the Machine Learning Process
- Example Machine Learning Scenarios
- A Closer Look at the Machine Learning Process
- Some Terminology
- Data Pre-processing
- Categorizing Machine Learning Problems
- Styles of Machine Learning Algorithms
- Training and Testing a Model
- Using a Model
Notas tomadas
Básicamente, ¿qué hace el Machine Learning? Busca patrones en los datos, y usa esos patrones para tratar de predecir el futuro.
¿Qué partes componen un sistema de ML?
- Los datos: que son los que continen los patrones
- El algoritmo: que es quien encuentra los patrones en los datos. Con esos patrones, se crea un:
- Modelo: que es quien reconoce los patrones en los datos que le envíe la:
- Aplicación: es el software que proporciona utilidad al usuario. Proporciona los datos actuales al modelo, y el modelo responde con la predicción
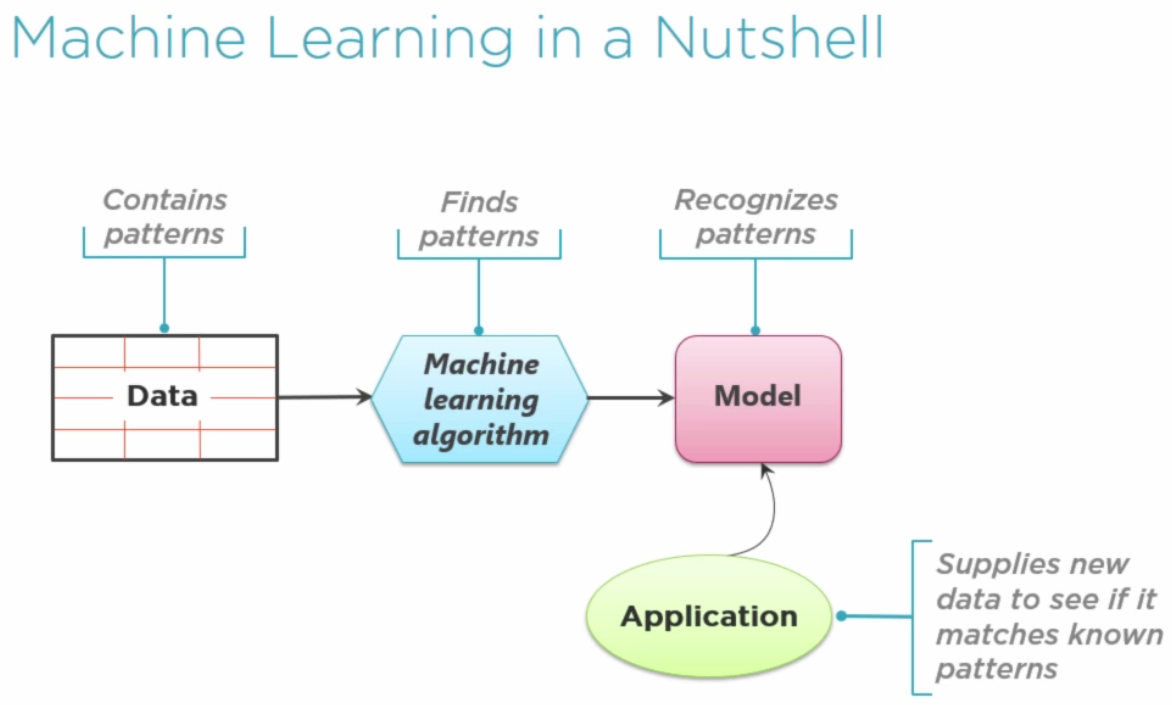
El proceso que sigue Machine Learning
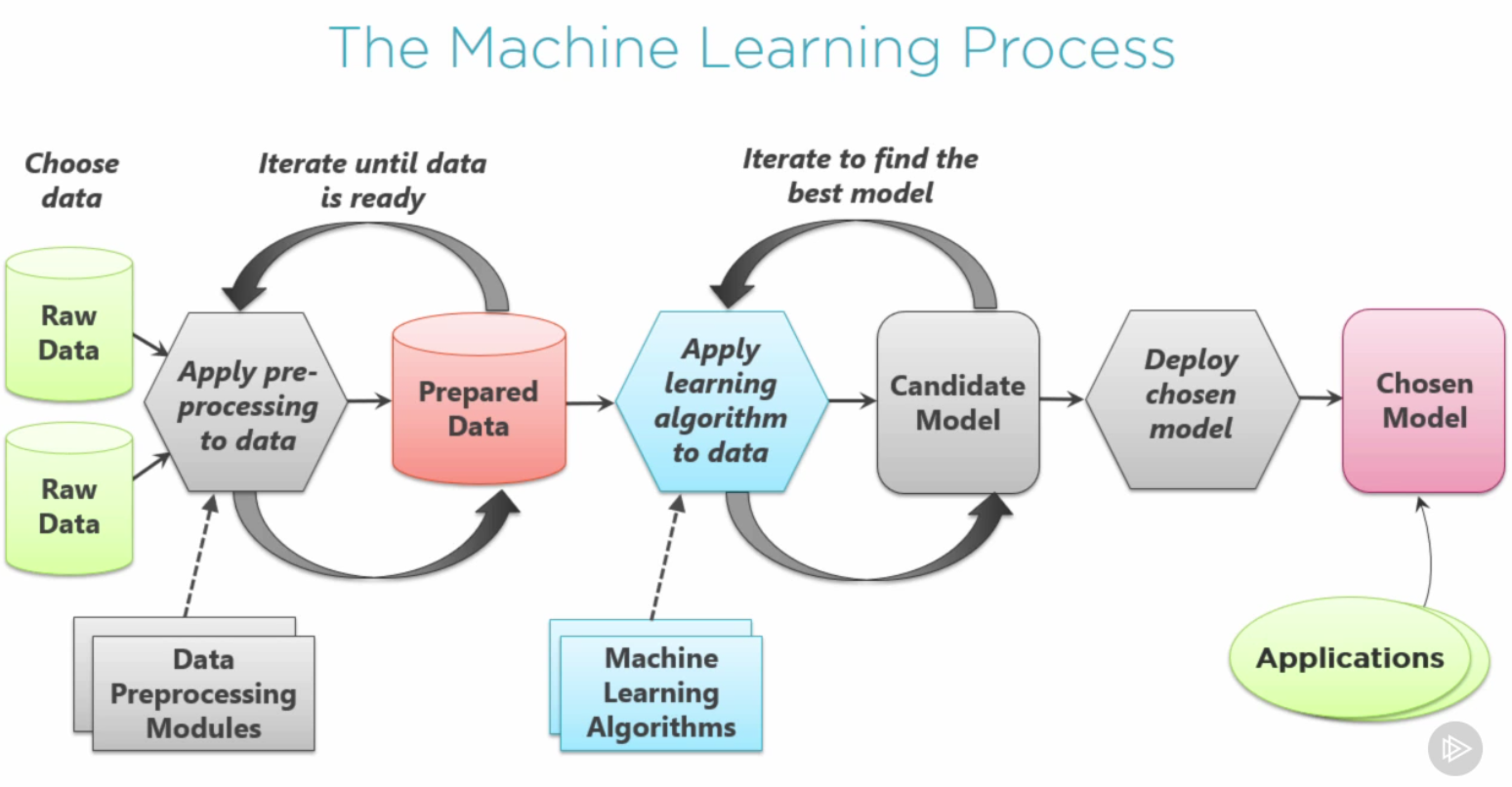
Partimos de datos en crudo. Pueden ser varias fuentes. Esos datos en crudo se pre-procesan (muchas veces con módulos proporcionados por terceras partes) para crear los Datos preparados. No vamos a acertar a la primera, por lo que este proceso es iterativo.
Con esos Datos preparados, aplicaremos algoritmos de aprendizaje (normalmente son algoritmos proporcionados también por terceras partes) para crear un Candidato a modelo. De nuevo, este proceso es iterativo.
Cuando estemos contentos con nuestro Candiato a modelo, lo desplegaremos llegando a un Modelo elegido. Nuestras aplicaciones se comunicarán con este modelo para obtener las predicciones.
Este es un proceso que no tiene porqué acabar. Si consideramos que el Modelo elegido no es lo suficientemente bueno, podemos empezar el proceso desde el principio, aplicando los aprendizajes que hayamos hecho en esta iteración global.
Terminología:
- Training data: son los datos preparados para crear el modelo. A crear el modelo se le llama entrenar el modelo
- Supervised learning: el valor que se quiere predecir está en los Training data. Por ejemplo, si se quiere saber si una transacción es fraudulenta, los datos de los que partimos, con los que entrenamos el modelo, deben contener transacciónes fraudulentas y no fradudulentas. En estos casos se dice que los datos están etiquetados (labeled)
- Unsupervised learning: lo contrario, el valor que se quiere predecir no está en los datos. Se dice que los datos están no etiquetados (unlabeled)
- Features: digamos que son las columnas de los Datos de entrenamientos (suponiendo que podemos ver esos datos como una tabla con filas y columnas).
- Target value: el valor que queremos predecir
Categorías de los problemas en ML:
- Regresiones: lineales,…
- Clasificación: cuando llega un nuevo dato, el modelo nos dirá a qué categoría pertenece
- Clustering: tenemos varios clusters (en lugar de categorías), cuando llega un nuevo dato debemos predecir a qué cluster pertenece. la diferencia con la Clasificación es que en Clustering, las categorías no las decidimos nosotros, si no que son descubiertas en los datos
Estilos de algoritmos de ML: árboles de decisión, redes neuronales, bayesianos (probabilidades), K-medias (clustering?)